The Storm That Is Not Slowing Down
Agentic AI has taken the industry and investors by storm. Technology is progressing exponentially, and conversations about AGI and the Singularity are no longer confined to academic papers and science fiction. They are showing up in board rooms, earnings calls, and government policy briefings.
Whether we land at full artificial general intelligence or something more nuanced, only time will tell. What I can tell you is that the machines are getting smarter, and the pace is not decelerating.
This is the first article in a series where I share my personal experience building an industry-specific LLM prototype. Not the theory. Not the hype. The real, hands-on, things-broke-and-I-fixed-them story born out of months of experiments with AI tools, RAG pipelines, and fine-tuning across different open-weight models. From building the dataset to deploying to production, and learning more from the failures than the successes.
A quick note on terminology. Throughout this series, when I say "LLM," I am using it as the broader industry term for large language models. But the models I am actually building and writing about are what the industry increasingly calls SLMs (Small Language Models), with a few billion parameters, purpose-built for a single domain. These are not frontier models (FMs) like GPT, Claude, or Gemini that run on hundreds of billions of parameters and try to do everything. These are focused, efficient, domain-specific models that trade general knowledge for deep expertise in one vertical. And the research backs this up: DeepSeek's distilled 7B model scored 92.8% on MATH-500 where GPT-4o managed 74.6% [9]. Scale is not destiny when focus and data quality are right.
Before I go further, a note on how this series is written. I use LLMs and agentic AI to support my storytelling. They give me additional creatine to expedite my writing abilities without hesitating in a non-native language. That does not mean this does not represent my thoughts. Every idea, every metaphor, every opinion in this piece is mine. The machine helps me say it more fluently.
A word about what to expect. My intent here is not to repeat academic research papers or write another dry technical walkthrough. I believe in storytelling. I believe in drawing parallels from walks of life, from philosophy, science, and literature, to explain what is happening in technology. If this is your first time reading my work, you will notice that I bring metaphors, quotes, and unexpected connections from other fields into the conversation. My goal is simple: I want you to not only learn about enterprise AI but also enjoy the journey along the way.
The Pluribus Syndrome
Foundation models like Claude, GPT, and Gemini are extraordinary. They can write poetry, debug code, explain quantum mechanics, draft legal contracts, and carry on a conversation about 15th-century Roman art for an Asian audience or translate Asian wisdom for the Western world, all in the same session. For the consumer market, this is a revelation. It is like having the most expensive mentors, philosophers, and teachers at your fingertip, available to anyone, anytime.
But here is where my mind goes. If you have watched Pluribus on Apple TV, you will know exactly what I mean. In the show, something happens to humanity and people start merging into a shared consciousness. Everyone knows what everyone else knows. Everyone feels what everyone else feels. Everyone is happy, content, and life is rosy. No more misunderstanding, no more conflict.
But Carol, the main character, does not buy it. She pushes back. Because she sees the cost: when everybody thinks together, nobody thinks for themselves anymore. You lose the thing that makes you you. The individuality, the perspective, the expertise that comes from deep personal experience.
That is what foundation models remind me of. One mind trained on almost everything ever written, wearing a single face for every user. You talk to it and it feels like one person, but behind that face is the collective knowledge of almost everything. And just like the hive mind in Pluribus, there is a cost. The depth gets sacrificed for breadth. The specialization gets dissolved into generalization.
“To know that you do not know is the best. To think you know when you do not is a disease.”
Lao Tzu
That is the difference between a foundation model and a domain-specific one in a single sentence. A foundation model thinks it knows your industry. It does not. But it will answer anyway: confidently, fluently, and incorrectly. That is hallucination. Not a bug, not a glitch. It is a model that was never taught to say "I do not know."
A well-trained domain-specific model is the opposite. It knows its domain deeply, and just as importantly, it knows where its domain ends. Ask it something outside its expertise, and it can be trained to tell you honestly that it does not have the answer. That is not a limitation. That is wisdom. That is Lao Tzu's point: real knowledge includes knowing your boundaries.
For consumer applications, the generalist approach is beautiful. Ask Claude anything, and you will get a remarkably thoughtful answer. But for enterprise? When a model knows everything about everything, individual brands lose their uniqueness. Their signature style dissolves. The proprietary knowledge that gives a company its competitive edge gets diluted into a sea of general-purpose intelligence that sounds the same for every organization.
A foundation model does not know your company's proprietary rate codes. And if those codes conflict with generic industry terms, even a RAG (Retrieval-Augmented Generation) pipeline can stumble, because the generalist model interpreting the retrieved context may still misrank or misapply the information. Think of it this way: RAG is like handing someone a stack of reference books and asking them to answer a question. They can look things up, but they are still a generalist reading the material for the first time. Fine-tuning, on the other hand, is muscle memory. The model does not need to look it up because it has internalized the knowledge. It does not know your internal systems from reading a document. It knows them the way an experienced employee does, because it was trained on them.
The CIO's Dilemma
I see this pattern constantly. CIOs are genuinely excited about agentic AI. They understand the potential. They are comfortable exploring, running proofs of concept, attending conferences, and building internal champions. But when it comes time to get projects on the floor, actually deployed, actually generating value, many hit a wall. A 2025 McKinsey Global Survey found that 88% of organizations are regularly using AI in at least one business function, yet nearly two-thirds have not begun scaling it across the enterprise. The jump from pilot to production remains one of the hardest gaps to close.
The wall is the Finance Office and the board.
You cannot walk into a board meeting and say "we should invest in AI because it is transformative." You need to say "we will reduce our average handling time by 40%, deflect 30% of tier-one support tickets, and the model will pay for itself in four months." CIOs are struggling to create that financial use case for agentic AI, and I believe a large part of the reason is that general-purpose models do not deliver domain-specific value that is easy to quantify. This is not a new problem. Traditional machine learning succeeded in enterprise precisely where it was applied to narrow, measurable tasks: fraud detection, recommendation engines, demand forecasting. The models that delivered ROI were the ones built for a specific job, not for everything at once.
Then layer on security and data sovereignty. Enterprise data, customer records, proprietary processes, and competitive intelligence cannot always be sent to a third-party API. Regulated industries have compliance requirements that make public model APIs a non-starter for certain workloads. The conversation quickly shifts from "can we use AI?" to "can we use AI our way, on our terms, with our data staying where it needs to stay?"
This is where industry-specific models change the equation entirely. According to IBM's Global AI Adoption Index (2023), data privacy (57%) is the single biggest barrier preventing organizations from adopting generative AI. The demand is not just for smarter models. It is for models that live inside your walls.
A Word on "Artificial" Intelligence
I want to take a brief detour, because language shapes thinking, and I think we are using the wrong word.
I do not believe in the term "Artificial Intelligence." There is nothing artificial in it. The intelligence is real. The comprehension is real. The ability to process a corpus of data and replicate knowledge patterns: that is a genuine form of intelligence, just not a biological one. I would call it "Machine Intelligence" if I were naming it today, but for simplicity, I will keep using AI. Just know that when I say it, I mean something real, not something fake. I have written about this idea in more depth in an earlier article, Demystifying AI: Recognizing the Authentic Intelligence.
This matters because the very real intelligence of these models creates very real challenges. The ability to comprehend vast amounts of data quickly and replicate that knowledge across domains is powerful. But knowing too much about all domains creates confusion. The model has seen medical literature, legal briefs, plumbing manuals, Shakespeare, agricultural science, and hotel operations manuals, and it treats all of that knowledge as equally relevant when generating a response.
The result is what we call hallucination, but I think a more honest term would be confusion from over-generalization. The model is not lying. It is pattern-matching across too many domains at once, pulling in associations that do not belong, blending contexts that should stay separate, and doing it all with the confidence of someone who has never been taught to say "that is outside my area."
Why Specialists Win
Here is the metaphor that resonates with me.
Why does my doctor need to know how to fix a windmill? Why does my plumber need to know Shakespeare? Why does a hotel manager need to know how to grow potatoes in a greenhouse?
We do not expect this of humans. When I hire a specialist, I want depth in their domain, not breadth across every domain. I want my cardiologist to know cardiology extraordinarily well. I do not need her to also be an expert in marine biology. In fact, if she spent half her training studying marine biology, I would be concerned about the quality of her cardiology.
So why do we accept this tradeoff in our AI systems?
The answer is that we do not have to. We can train machines for domain knowledge: focused, efficient, and cost-effective. A model that knows one industry deeply will outperform a model that knows every industry superficially, at least for the tasks that matter to that industry. And it will do it at a fraction of the cost, with fewer hallucinations, and with responses that actually sound like they come from someone who works there.
The Overqualification Trap
Here is a parallel that I think enterprise leaders will immediately understand, because they have lived it.
Every hiring manager has seen it: a candidate with three PhDs, fifteen years of experience across six different industries, and a resume that looks like a Wikipedia table of contents. On paper, they are the most qualified person in the room. In practice? They often struggle to integrate into a specific role because their knowledge is spread so thin across so many domains that they lack the focused expertise the job actually requires. They are overqualified, and paradoxically, that makes them underperforming for the specific task at hand.
In machine learning, overfitting happens when a model learns the training data too well, including its noise and idiosyncrasies, and loses the ability to generalize. In enterprise, an overqualified hire often brings patterns and assumptions from other industries that do not translate. Both situations share a root cause: too much broad knowledge applied to a narrow problem.
I believe enterprise will adopt machine intelligence at scale when they see value the way they see value in human resources. You do not hire a generalist when you need a specialist. You should not deploy a general-purpose model when you need domain expertise.
And the economics are moving in the right direction. Compute costs are falling. Open-weight models are improving rapidly. The cost balance between hosting your own purpose-built LLM and paying per token on a general-purpose API is shifting. Today, the math already works for many use cases. Tomorrow, it will work for most. The question is not whether domain-specific models make sense. It is how quickly your organization can build one.
The Experiment
Theory can only take you so far. At some point, you have to get your hands dirty and test whether the ideas actually hold up in practice.
This approach reminded me of something I learned early in my career as a technology leader. When building large project teams, I found that hiring fresh college graduates with strong technical foundations and training them for three weeks on the specific project domain consistently outperformed hiring expensive senior consultants with broad but shallow knowledge. Forty-plus people, lower cost, more agility, and a fresh perspective unclouded by assumptions from other industries. The same principle applies to models.
So I ran the experiment. I took an open-weight foundation model, a 7-billion-plus parameter model, which is small by today's standards, and fine-tuned it for a specific industry vertical. The goal was simple: make it an expert in one domain, test whether it could outperform general-purpose models on domain-specific tasks, and see what it actually costs.
Here is what happened.
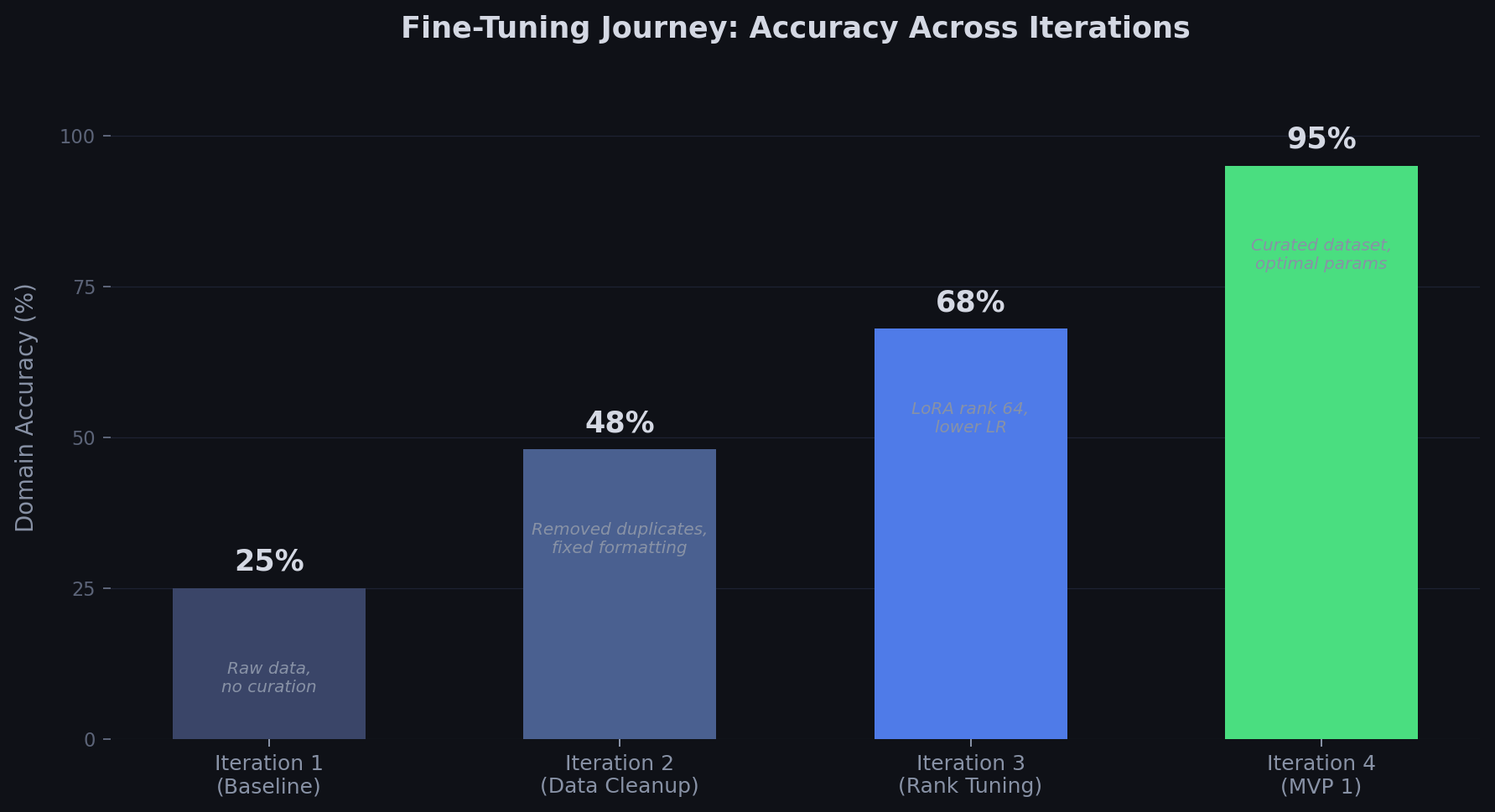
Phase 1: Everything Was Broken
The first training run was a humbling experience. The model's accuracy on domain-specific questions ranged from 0% to maybe 50% on a generous day, and it hallucinated constantly. Ask it a straightforward question about the domain, and it would generate a plausible-sounding answer that was completely fabricated. Not a single proprietary term was correct. The model was confidently wrong about everything.
Phase 2: The Data Quality Reckoning
Debugging led me to the training data. I ran a deduplication analysis and discovered that 77% of the training data was duplicated. I thought I had over 5,000 training examples. After removing duplicates and near-duplicates, I had roughly 1,000 unique ones.
The lesson is counterintuitive but consistent: in fine-tuning, data quality dominates data quantity by an enormous margin. Interestingly, researchers have since shown similar findings formally. The LIMA paper [1], for instance, found that fewer than 1,000 carefully curated examples can match datasets fifty times larger.
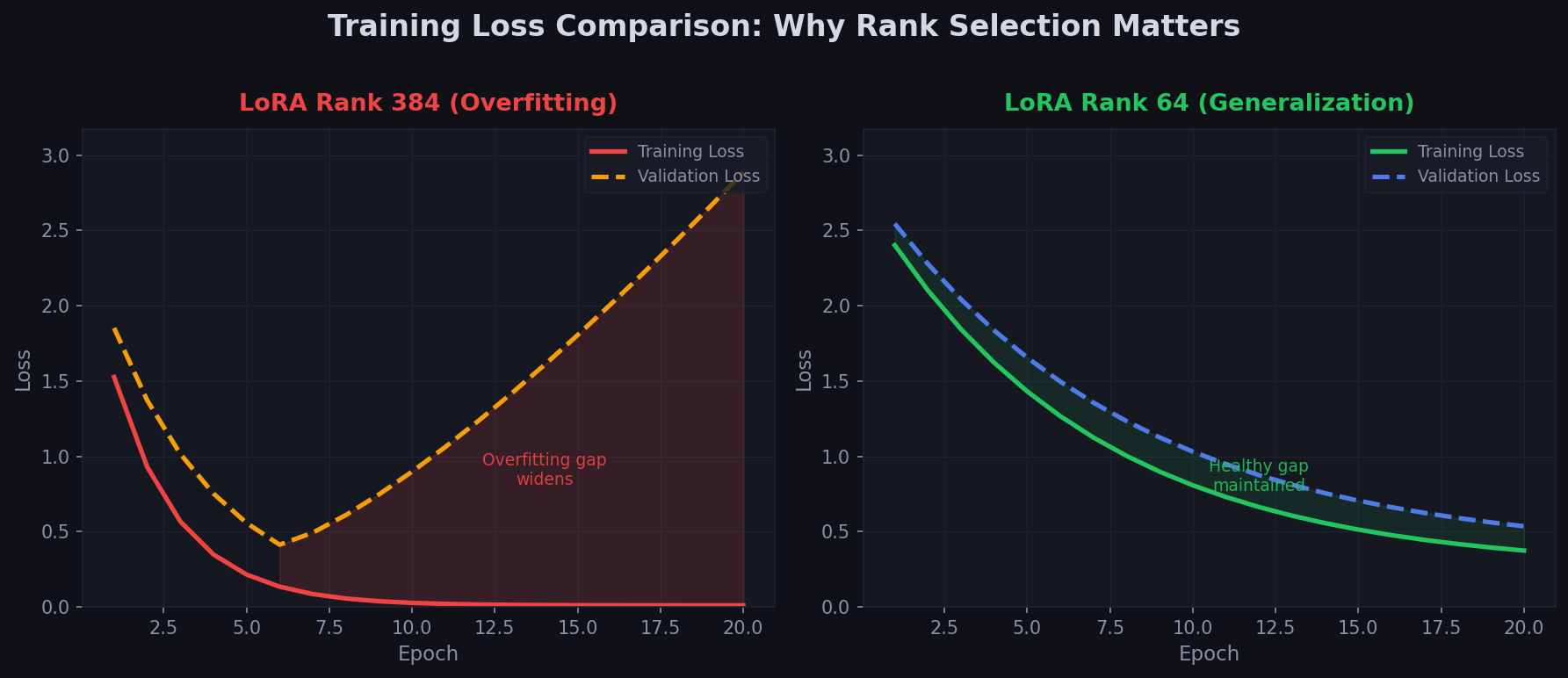
Phase 3: The Overfitting Trap
With clean data, the next training run was better but still wrong in a different way. The model would sometimes parrot training examples verbatim rather than generalizing. It had memorized instead of learned.
The culprit was the LoRA rank, the parameter that controls how many trainable parameters the adapter injects into the base model. I had set it to 384, thinking more capacity meant better learning. For a dataset of fewer than 2,000 examples, this was wildly excessive. The model had enough parameters to memorize every training example rather than extracting patterns from them.
Reducing the LoRA rank from 384 to 64 was the turning point. The model stopped memorizing and started generalizing. For those curious about the mechanics, the LoRA [2] and QLoRA [3] papers explain why this works at a theoretical level.
Phase 4: Production Deployment
The final model was trained using QLoRA (Quantized Low-Rank Adaptation) on a single GPU. Four iterative training cycles. Each training run cost approximately $15, a figure that reflects the proof-of-concept environment: a small, curated dataset of roughly 1,000 unique examples and a 7-billion parameter base model. Production workloads with larger datasets and longer training schedules will cost more, but the order of magnitude remains far below what most enterprise leaders expect. The model was deployed to Amazon Bedrock Custom Model Import, making it available through a standard API with pay-per-token pricing and no idle costs.
The results:
95% accuracy on a 62-scenario evaluation suite covering 10 domain categories
Near-zero hallucinations on domain-specific questions; the model stopped fabricating information
7 billion parameters small enough to be cost-effective, large enough to be capable
A focused model punches above its weight. Others have seen this too. BloombergGPT [4], a 50-billion parameter model built for finance, showed the same principle at a much larger scale: domain-specific training fundamentally changes what a model can do within its vertical.
What I Learned (The Short Version)
Five things I would tell anyone starting this journey:
What Is Next
In the upcoming articles, I will walk you through my experience and learnings by applying this knowledge to the industry I am currently working closely with. I will not reveal the industry just yet, but I will tell you this much: it is a customer-facing industry, one that is highly regarded and respected for its brand value. Loyalty programs, brand signature, and the consistency of the guest experience are the keys to success in this space.
A hive-mind model, one that speaks the same way for every brand, should not dilute the uniqueness that makes each company in this industry stand apart. The omni-channel experience delivered to customers should be as unique as the training, hospitality, and treatment that the brand's own agents display every day. When your AI speaks, it should sound like your brand, not like everyone else's.
The Series Ahead
This is Part 1 of a multi-part series on building enterprise AI with industry-specific models. In Part 2, I will reveal the specific industry use case and walk through the domain analysis that made it an ideal candidate for fine-tuning. Part 3 will dive into training data curation, the art of building a dataset that actually teaches the model what you need it to know. From there, Part 4 covers the deployment architecture, from training to production on AWS. And in Part 5, I will share the evaluation frameworks I built to measure what actually matters in a domain-specific model.
Each article will blend the strategic perspective with hands-on technical detail. If you are a technology leader evaluating whether to build domain-specific AI, I want to give you both the business case and the implementation playbook.
Further Reading and References
As I continue learning and building in this space, these research papers are playing a pivotal role in providing direction to my work. I did not start with them, but the deeper I go, the more valuable they become.
- Zhou, C., Liu, P., Xu, P., et al. (2023). LIMA: Less Is More for Alignment. arXiv:2305.11206. arxiv.org/abs/2305.11206 Shows that 1,000 carefully curated examples can match datasets 50x larger. Worth reading if you are building fine-tuning datasets.
- Hu, E. J., Shen, Y., Wallis, P., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685. arxiv.org/abs/2106.09685 Explains the theory behind Low-Rank Adaptation and why rank selection matters.
- Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized Large Language Models. arXiv:2305.14314. arxiv.org/abs/2305.14314 Covers how 4-bit quantization combined with LoRA makes fine-tuning on a single GPU practical.
- Wu, S., Irsoy, O., Lu, S., et al. (2023). BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564. arxiv.org/abs/2303.17564 A large-scale example of domain-specific training outperforming general-purpose alternatives within a vertical.
- Wang, Y., Kordi, Y., Mishra, S., et al. (2023). Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv:2212.10560. arxiv.org/abs/2212.10560 Useful background on synthetic training data generation for those looking to scale datasets.
- Qwen Team. (2024). Qwen2.5 Technical Report. arXiv:2412.15115. arxiv.org/abs/2412.15115 Technical details on the Qwen2.5 family, including the 7B-Instruct variant used in this experiment.
- McKinsey & Company. (2025). The State of AI in 2025: Agents, Innovation, and Transformation. McKinsey Global Survey, November 5, 2025. mckinsey.com Reports that 88% of organizations are regularly using AI in at least one business function, yet nearly two-thirds have not begun scaling across the enterprise.
- IBM & Morning Consult. (2023). IBM Global AI Adoption Index 2023. Published January 10, 2024. newsroom.ibm.com Survey of 8,584 IT professionals across 15 countries found data privacy (57%) is the top barrier preventing enterprise generative AI adoption.
- DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948. arxiv.org/abs/2501.12948 Distilled 7B model scored 92.8% on MATH-500 where GPT-4o scored 74.6%, demonstrating that reasoning capabilities transfer effectively to small models.
Up Next in the Series
Part 2 applies a five-dimension domain fitness framework to the Travel and Tourism industry and narrows to hospitality as the case study for the rest of the series.